
FIM Evaluation Part 3
Yesterday I tested out the CodeLlama FIM capabilities using the human-eval-infilling tool from OpenAI. I found the smallest 7b base model got ~76% accuracy on the single-line evaluation (for 100 tasks) when the temperature was set to 0. Today I’m going to measure the effect of temperature on the FIM accuracy, and try out the new DeepSeek Coder V2 FIM capabilities.
Llama temperature variation
When I first fired up the Code Llama model yesterday and ran a few manual tests it produced some very chaotic results, including generating Chinese characters when I expected a simple python completion. I very quickly set the temperature to zero and found that solved the problem.
Later when I ran the eval on Code Llama I ran each task 5 times to estimate the probability of getting a correct result at least once in k attempts (pass@k) for k = 1, 3, 5, I found all were the same. This is good because when temperature is zero the results should be the same.
Previous investigation of Claude, GPT, and Gemini (where I don’t have control over the temperature) I can see pass@k improves as k gets larger, so I expect some amount of temperature is better than zero. Today I’ll figure out where that sweet-spot is for this eval.
I ran codellama-7b-code on 200 tasks from the “single-line” evaluation dataset for a range of temperatures T: [0.0, 0.25, 0.5, 0.75, 1.0]. The results show pass@1 is optimal around T = 0.2 whereas pass@3, pass@5, and pass@10 show optimal results for T = 0.75.
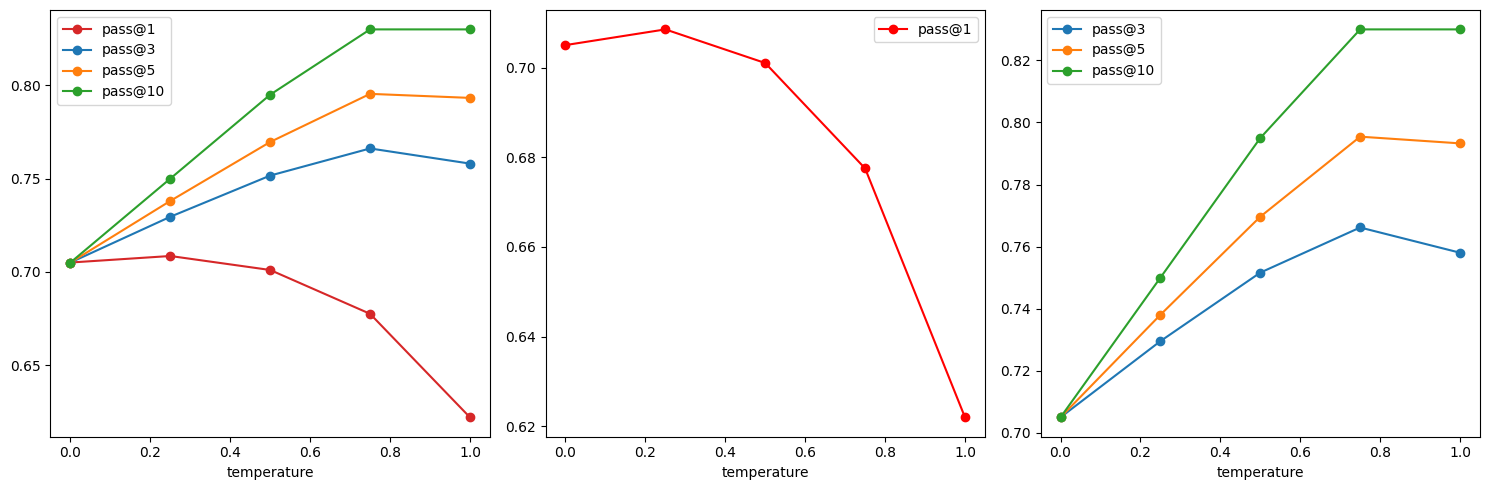
Now my question is what k should we optimize for in pass@k. Intuitively it seems like we should care about relatively lower k values because we want an autocompletion model to be predictable. It seems ok to have the model reliably get certain classes of autocompletion problems wrong as long as it reliably gets the rest of them correct. But this is probably something worth playing with in live coding situations and get a feeling for which one feels better. It’d also be possible to run live experiments on a large enough user-base and compare the acceptance rate over time as you vary the temperature.
That said, none of these metrics come close to the performance of Gemini in our code completion task (96%-99%), so no matter what temperature we choose, it’s not worth considering Code Llama 7b, but we should keep this in mind when we try out its bigger brothers.
DeepSeek Coder
Instead of moving on to assess larger models right away I decided to try out the new DeepSeek Coder V2.
I chose to test out deepseek-coder-v2:16b-lite-base-q4_0 which you can download using ollama.
There are a lot of different quantization options, and I wasn’t sure exactly which one would be the best, but this seemed like an ok place to start.
The results were awesome! I ran 100 tasks of the “single-line” eval and came out with results better than Gemini (the best performing model I’ve tested so far).
Here is an overview of all the models I’ve assessed so far for the “single-line” evaluation with 100 tasks:
| model | haiku 3.5 | gpt-4o-mini | gemini-1.5-flash | code-llama (7b) | deepseek-coder-v2 (7b) |
|---|---|---|---|---|---|
| pass@1 | 0.17 | 0.39 | 0.96 | 0.76 | 0.97 |
| pass@3 | 0.21 | 0.41 | 0.98 | 0.769 | 0.995 |
| pass@5 | 0.24 | 0.43 | 0.99 | 0.77 | 1.0 |
| cost ($) | $0.39 | $0.06 | $0.03 | $0 | $0 |
The prompt for FIM taken from the ollama website is:
<|fim▁begin|>{prefix}<|fim▁hole|>{suffix}<|fim▁end|>This is very promising! Tomorrow I’m going to try to hook this up in Satyrn to see how it feels. See if the latency running on my laptop makes it feel usable.